【書式】
【コード】
import pandas as pd
import seaborn as sns
sns.set()
df=sns.load_dataset("iris")
print("先頭5データ",df.head())
print("\n")
print(df.info())
【結果】
import pandas as pd
import seaborn as sns
sns.set()
df=sns.load_dataset("iris")
print("先頭5データ",df.head())
print("\n")
print(df.info())
先頭5データ sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length 150 non-null float64
1 sepal_width 150 non-null float64
2 petal_length 150 non-null float64
3 petal_width 150 non-null float64
4 species 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
None
【書式】
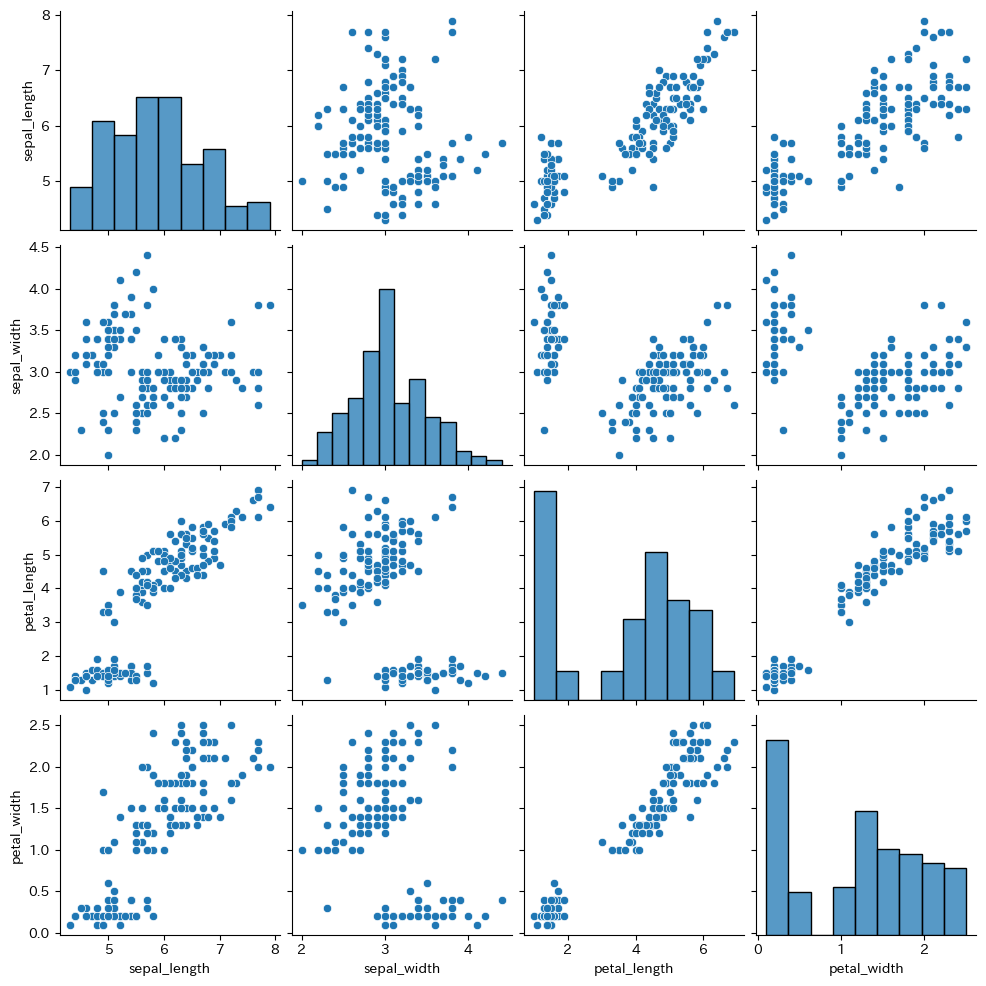
ライブラリ:pandas,matplotlib,seaborn
書式
sns.pairplot(data=df)
plt.show()
オプション
kind="reg" : 回帰曲線を追記する
【コード】
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
df=sns.load_dataset("iris")
sns.pairplot(data=df)
plt.show()
【結果】
【書式】
相関行列の表示
df.corr()
特定列を削除する
df.drop("列名",axis=1)
【コード】
%matplotlib inline
import pandas as pd
import seaborn as sns
sns.set()
df=sns.load_dataset("iris")
# species 列は文字列なので落とす。
# 「corr()メソッドではデータ型dtypeがobjectの列は除外される」らしいのだが・・・
df=df.drop("species",axis=1)
print(df.corr())
sns.heatmap(df.corr(),annot=True,vmax=1,vmin=-1,center=0)
plt.show()
【結果】
sepal_length sepal_width petal_length petal_width
sepal_length 1.000000 -0.117570 0.871754 0.817941
sepal_width -0.117570 1.000000 -0.428440 -0.366126
petal_length 0.871754 -0.428440 1.000000 0.962865
petal_width 0.817941 -0.366126 0.962865 1.000000

【書式】
Take2 の結果から、次の組み合わせの相関が高そうなので、この散布図を描いてみる。
sepal_length と petal_length
sepal_length と petal_width
df.plot.scatter(x="横軸の列名",y="縦軸の列名",color="色")
【コード】
%matplotlib inline
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
import pandas as pd
df=sns.load_dataset("iris")
df.plot.scatter(x="sepal_length",y="petal_width",color="b")
plt.title("sepal_lengthとpetal_width")
plt.show()
df.plot.scatter(x="sepal_length",y="petal_length",color="b")
plt.title("sepal_lengthとpetal_length")
plt.show()
【結果】
/usr/local/lib/python3.10/dist-packages/IPython/core/pylabtools.py:151: UserWarning: Glyph 12392 (\N{HIRAGANA LETTER TO}) missing from current font. fig.canvas.print_figure(bytes_io, **kw)

/usr/local/lib/python3.10/dist-packages/IPython/core/pylabtools.py:151: UserWarning: Glyph 12392 (\N{HIRAGANA LETTER TO}) missing from current font. fig.canvas.print_figure(bytes_io, **kw)

【書式】
df["列名"].unique()
【コード】
import seaborn as sns
import pandas as pd
df=sns.load_dataset("iris")
df["species"].unique()
【結果】
array(['setosa', 'versicolor', 'virginica'], dtype=object)
【書式】
データフレームの絞り込み
df[df["列名"]=="検索条件"]
【コード】
%matplotlib inline
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
import pandas as pd
df=sns.load_dataset("iris")
onespecies="setosa"
one=df[df["species"]==onespecies]
# species 列は文字列なので落とす。
one=one.drop("species",axis=1)
sns.heatmap(one.corr(),annot=True,vmax=1,vmin=-1,center=0)
plt.title("onespecies",fontsize=18)
plt.show()
【結果】

【書式】
データフレームの絞り込み
df[df["列名"]=="検索条件"]
【コード】
%matplotlib inline
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
import pandas as pd
df=sns.load_dataset("iris")
# 品種設定
onespecies="setosa"
one=df[df["species"]==onespecies]
# species 列は文字列なので落とす。
one=one.drop("species",axis=1)
sns.heatmap(one.corr(),annot=True,vmax=1,vmin=-1,center=0)
plt.title(onespecies,fontsize=18)
plt.show()
# 品種設定
onespecies="versicolor"
one=df[df["species"]==onespecies]
# species 列は文字列なので落とす。
one=one.drop("species",axis=1)
sns.heatmap(one.corr(),annot=True,vmax=1,vmin=-1,center=0)
plt.title(onespecies,fontsize=18)
plt.show()
# 品種設定
onespecies="virginica"
one=df[df["species"]==onespecies]
# species 列は文字列なので落とす。
one=one.drop("species",axis=1)
sns.heatmap(one.corr(),annot=True,vmax=1,vmin=-1,center=0)
plt.title(onespecies,fontsize=18)
plt.show()
【結果】



【書式】
データフレームの絞り込み
df[df["列名"]=="検索条件"]
散布図行列描画
ライブラリ:pandas,matplotlib,seaborn
書式
sns.pairplot(data=df)
plt.show()
オプション
kind="reg" : 回帰曲線を追記する
【コード】
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
df=sns.load_dataset("iris")
# 品種設定
onespecies="setosa"
one=df[df["species"]==onespecies]
# species 列は文字列なので落とす。
one=one.drop("species",axis=1)
sns.pairplot(data=one,kind="reg")
plt.show()
【結果】

【書式】
ライブラリ:pandas,matplotlib,seaborn
書式
sns.pairplot(data=df)
plt.show()
オプション
hue="列名" : 色分け基準
【コード】
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
df=sns.load_dataset("iris")
sns.pairplot(data=df,hue="species")
plt.show()
【結果】

【書式】
dfをCSVに書き出す。
【コード】
import pandas as pd
import seaborn as sns
df=sns.load_dataset("iris")